
ControlNet 官方的其它特殊效果主要有 Shuffle、Tile、Inpaint、IP2P、Reference,其中Tile和Inpaint會花比較多篇幅就之後另外再介紹,這篇就先來看Shuffle & IP2P & Reference這三種ControlNet成像效果。
Shuffle
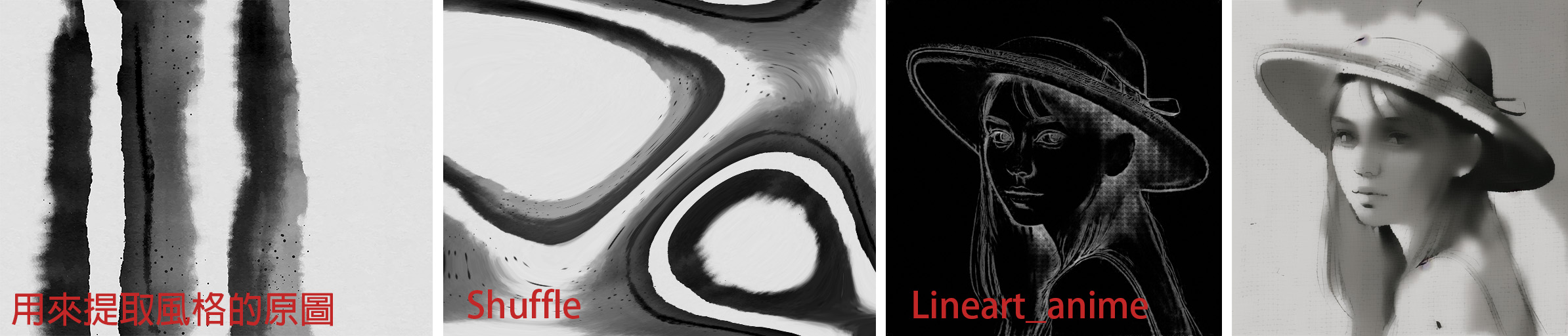
Shuffle預處理器會將原本的圖片畫面打散重新洗牌(而且每都是隨機亂數提取),所以同一張原圖每次提取出的預處理圖被打散的樣式會都不一樣。但重點就是提取出原圖的顏色/風格,進而去影響新生成圖像的整體畫風/色調。
先用文生圖簡單生成一張真人照片
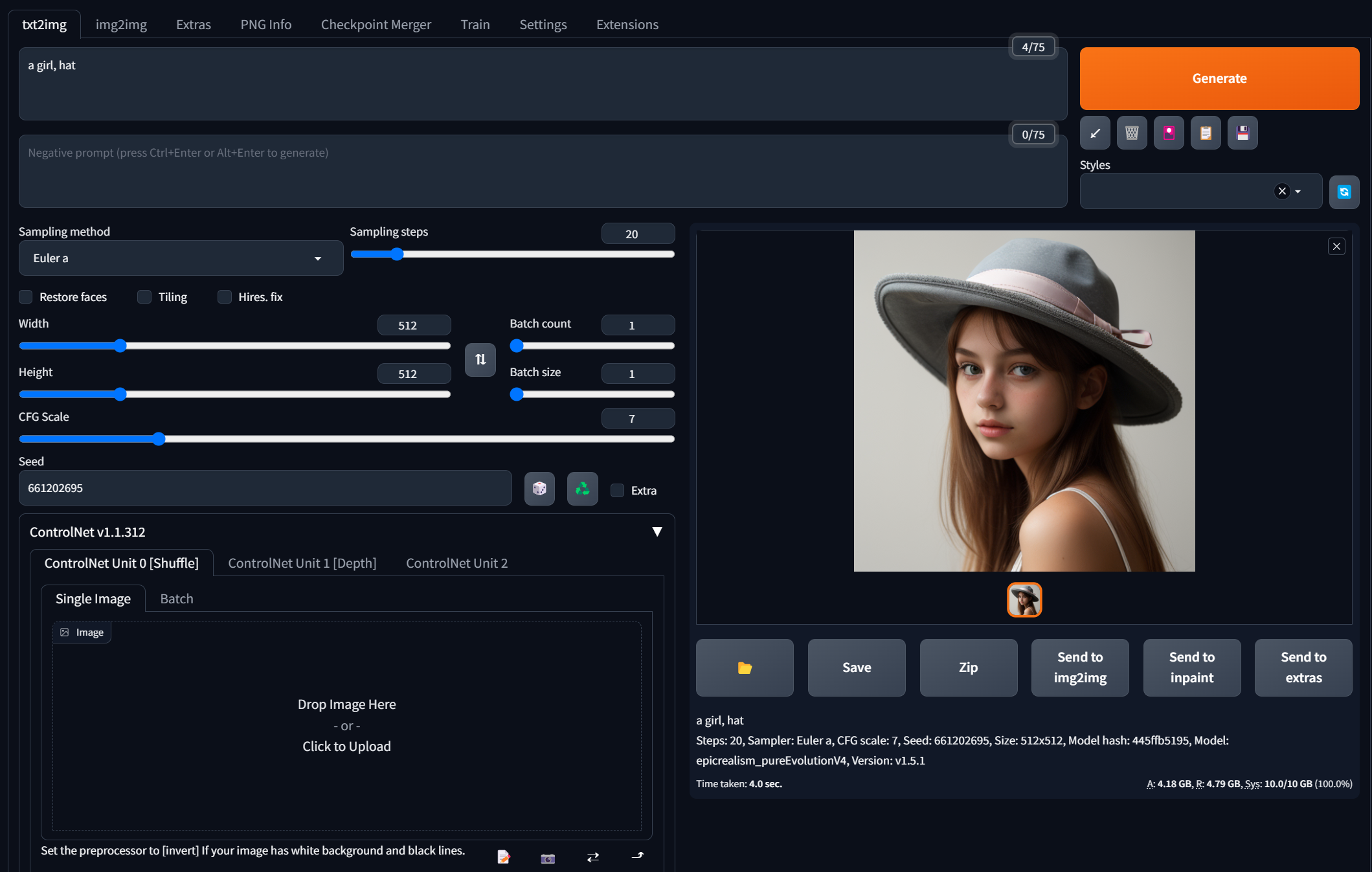
加入ControlNet Shuffle。這裡雖然所有設定不變,連Seed值也固定住,不過加入ControlNet Shuffle的影響後,風格移植了,但同時無法固定住照片原本的構圖。
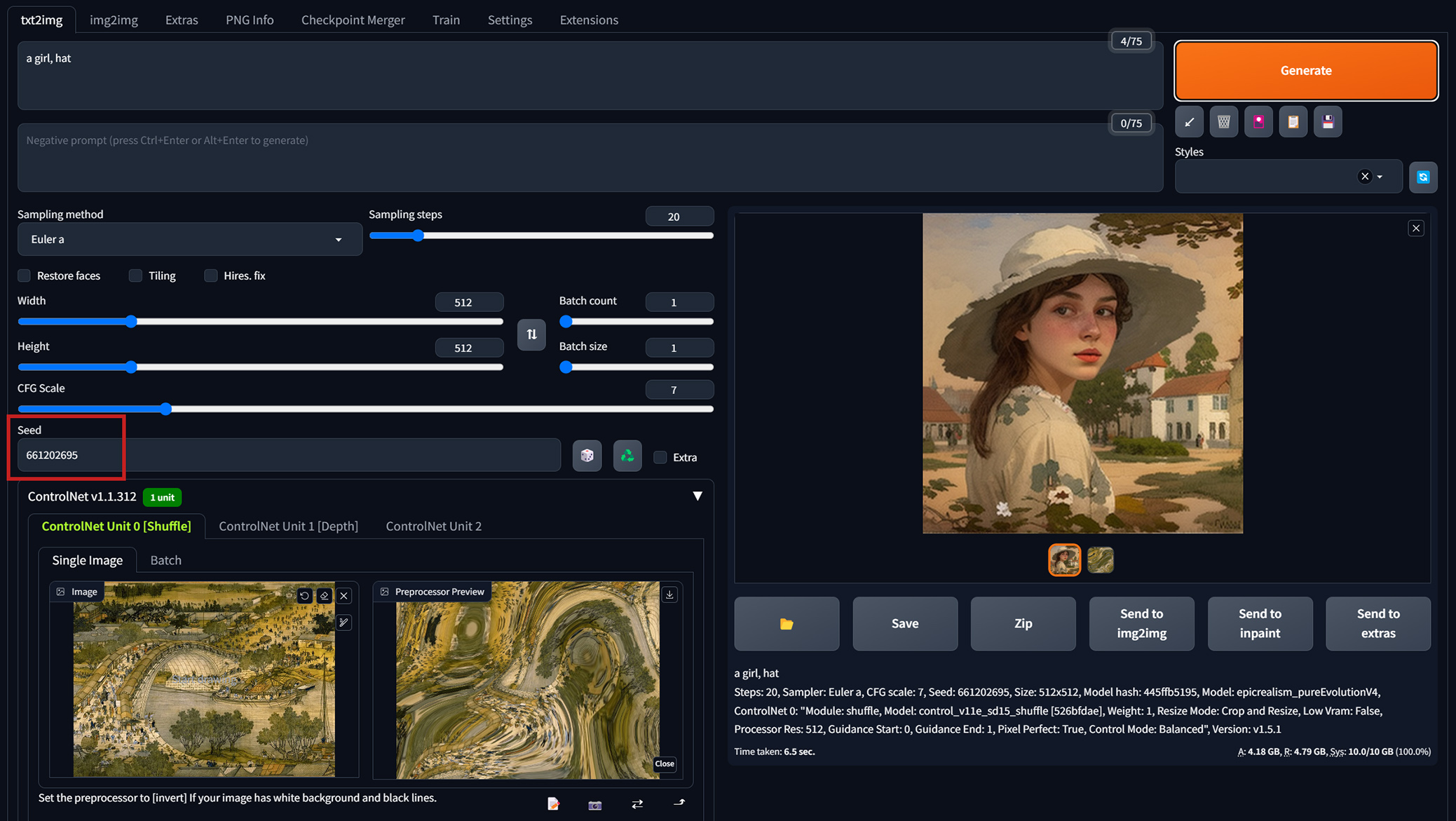
前面構圖改變太多的問題,雖然也可透過把Control Weight權重調低的方式改善,但又怕權重愈調低了,風格移植的效果愈不明顯。那不如不要去改變權重,只要再加入第二個ControlNet的Canny線條約束來限制住大致的輪廓外觀就好。
再多加一個Canny的線條約束,如此,算是有把清明上河圖的風格/色調移植到新圖上了吧?
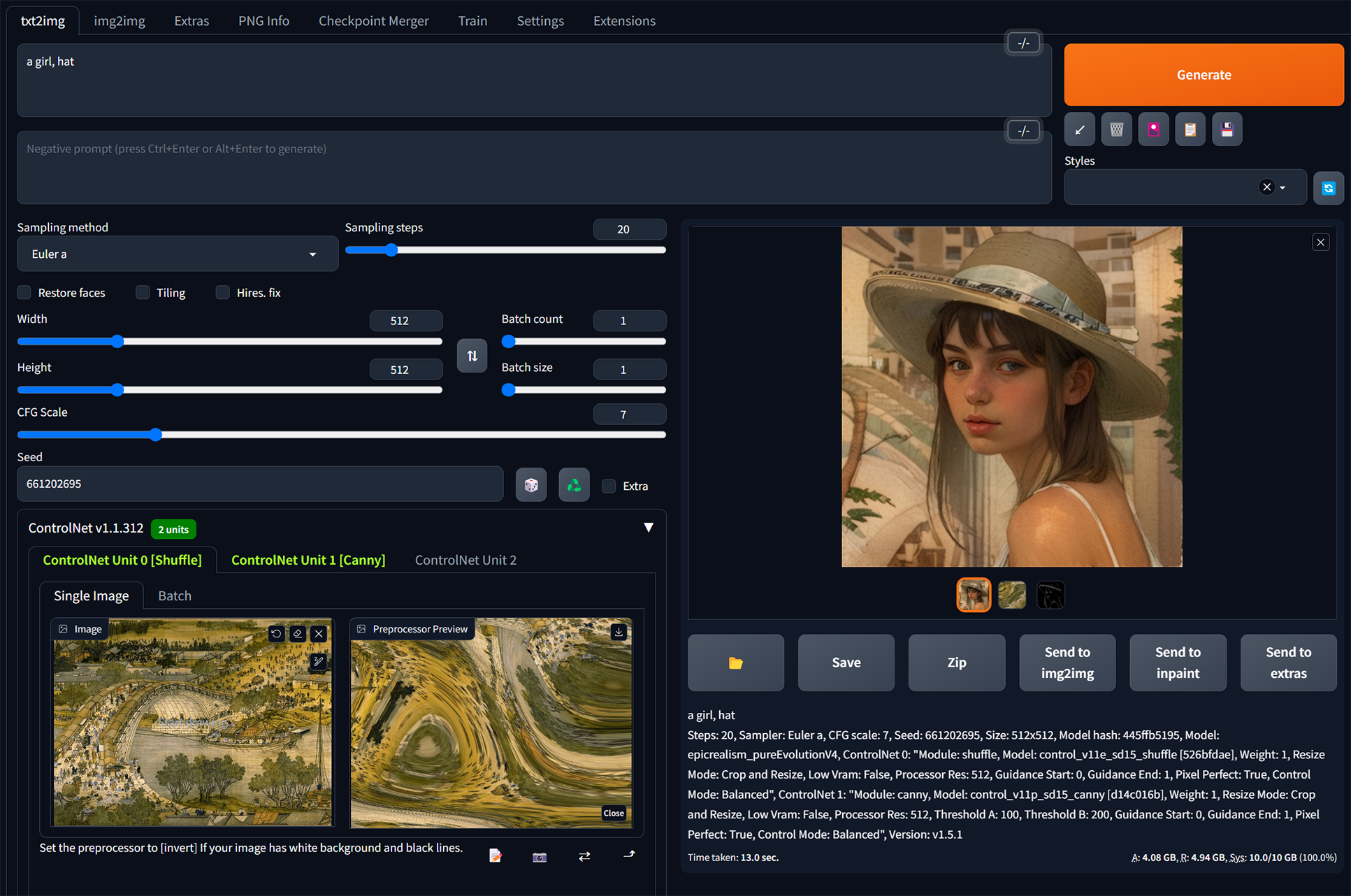
Shuffle的權重預設的1就差不多很剛好,再低風格效果不明顯,再高又會畫面崩壞 :

而前面說的透過把Control Weight權重調低的方式來改善畫面構圖不要被改變太多,但實測再低的權重也是無法很準確有效地定住原構圖的細節,不如線條約束實用 :

再來一張套上水墨風格的成像。到這裡一直都是用真人風格的Checkpoint模型,人臉的部分看起來就只是轉黑白色調而已,沒有水墨畫風的質感。
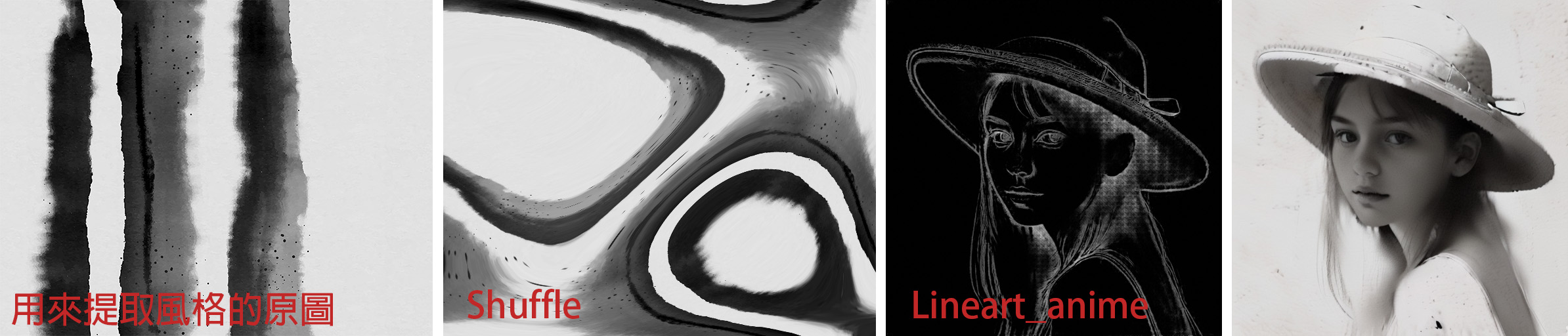
如果換成專畫卡通人物的Checkpoint模型(AnythingV3),這樣好像風格移植的效果更明顯些,不是只有顏色移植。所以,在做風格轉換時也需要注意一下所使用的Checkpoint模型與最終想要成像的風格效果搭不搭配。ControlNet提取風格的原圖如果是卡通動畫、二次元、或是像這張水墨風等,想要不是只有顏色/色調的移植,而是要連畫風的質感都時展現出來時,那麼就要記得避開使用專畫三次元真人寫實風格的Checkpoint模型。
IP2P
IP2P沒有預處理器,它的效果就是可以把一張原圖加上提示詞描述(ex. “make it on fire”),來轉換場景狀態,例如讓場景起火、下雪變冬天…..等。

這邊在提示詞的部分,官網上介紹註明 : Also, it seems that instructions like “make it into X” works better than “make Y into X”
從下面的人像圖所下的提示詞就可看出差別。照常理,我會在提示詞裡寫上”make her on fire”或是”make her snow”。但可以明顯發現,這樣原圖的人物會有所改動,幾乎是變成另外一個人。

但如果照官網指示,不管是針對場景還是人物,提示詞的開頭都統一寫”make it ……”,會比較理想。如下圖,原圖人物的長相特徵有保留住的情況下做到了場景狀態轉換。

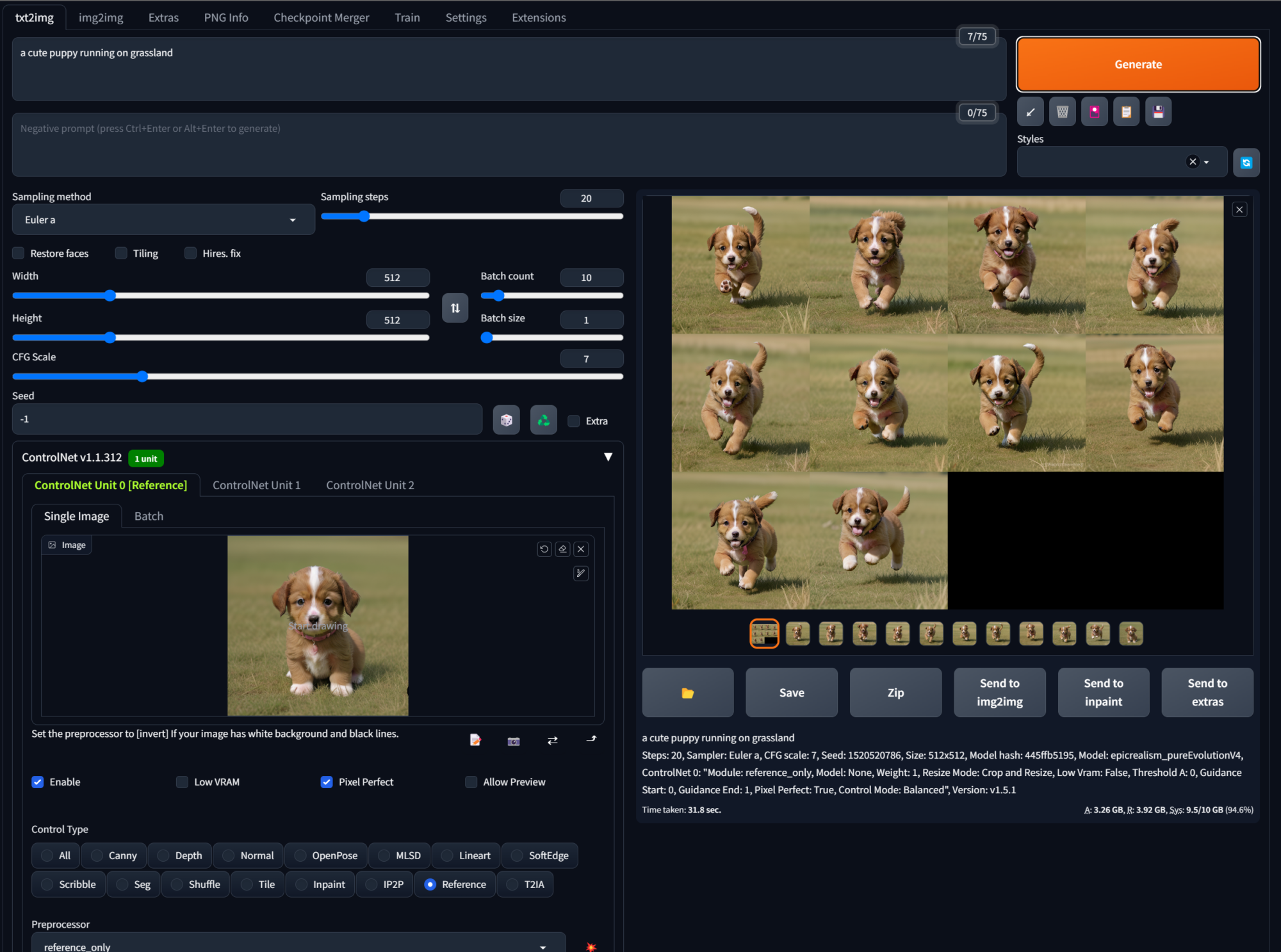
Reference
Reference的功用是用來生成與原圖風格內容類似的圖。使用Reference目前有3種預處理器,但並不需要有對應的Control Model。
在官網的示範中(下圖的圖片來源 : https://github.com/Mikubill/sd-webui-controlnet),看起來似乎很好用,好像用一張參照圖,就可以去生成參照圖片中人物/動物的各種變化圖來(固定住人物/動物的特徵去生成變化不同姿態/表情)。
(Prompt “a dog running on grassland, best quality, …”)
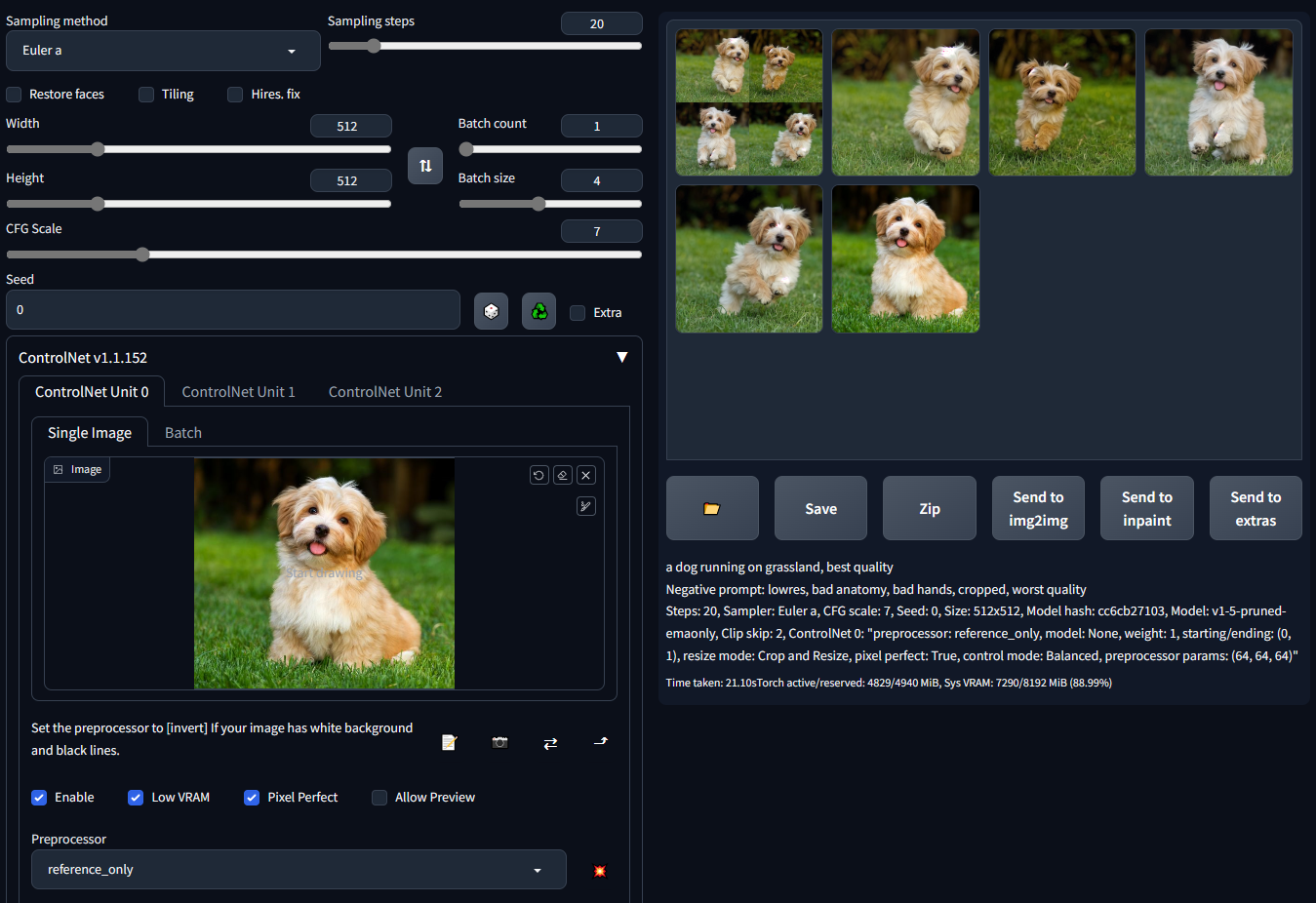
如此一來,就可以用一張圖去生成訓練LoRa模型時要用到的多張同個人物角色,但不同臉部表情/角度的圖片,或是說,一張參考照片就能搞定固定住人物特徵實現人設統一,那是不是就不需要LoRa了?
看上面狗在草地上奔跑的例子效果很好,但如果放在人物身上時呢 ?
下面圖例讓原圖中戴墨鏡,沒有表情的女孩,加上微笑。在3種Reference預處理器下的效果 :
提示詞 : a girl wearing sunglasses, smile
最後面放了一張關閉ControlNet Reference效果,只有提示詞產出的圖來對比。感覺Reference差不多就是固定住髮型、和在畫面中大致的姿勢構圖。至於你說人的五官長相有沒有像,同一個模型的這些人臉看久了我實在有些臉盲了@@

Reference 控制下連刷10張圖 : 有的髮型固定住了,有的衣服特徵固定住。

我用動物測試時真的都挺像的,可以連刷10張奔跑姿勢都沒問題,看起來10張都是同一隻狗沒錯。
但真人的五官長相我實在刷不出這樣都固定住的效果。而且像上面載太陽眼鏡女孩的例子,如果提示詞裡沒去交代有戴太陽眼鏡的話,那就只會生成一個笑臉女生,差不多的頭髮長度,上半身正面照。如此的話,那我用不用Reference好像差別意義不太大?稍微可輔助固定特徵,但很大呈度上都是靠提示詞細描述和所使用的Checkpoint模型?
最後不死心,再拿張長相比較有辨識度的人像來測看看,加上Reference,看看SD會參照還原畫出怎樣類似的特徵來。

提示詞只有”a man, smile”。看得出來,Reference抓住灰白髮色+自然捲特徵(這個是我提示詞沒說明,很明確是Reference的功勞)。

總之,目前為止,Referenc我還沒能玩出真的像網上有些標題說的這麼厲害,可以取代LoRa,人設統一之類的地步(是朝這個方向沒錯,只是離穩定品質還有很大的差距)。有時訓練模型的樣本數不夠時或許這個Reference現在可以幫忙加減多提供一些變化的樣本圖,但至於其它,還是先不要太過期待Reference的效果,等它之後再進化/優化的版本/演算效果出現時再說吧~
另外,補充一下前面沒說到Reference預處理器下有個”Style Fidelity (only for “Balanced” mode) “的參數可調整,它是用來控制Reference風格保真度的高低(只在Control Mode是Balanced模式下有效)。
實測圖如下,我是覺得一般都用預設的0.5就可以了,拉低少了相似度,拉太高生成的圖又很容易會畫面崩壞。


看起來大致上就是Reference_only和Reference_adain+attn,保真度約預設的0.5剛好,而Reference_adain有需要時可以稍微往1的方向拉高,也不至於出現畫面崩壞。

~下方拍手按個讚(每人最多可按5次讚),鼓勵一下吧,您的鼓勵就是店小二持續發文的動力~ 感謝 : ) ~
Leave a Reply