
在SD WebUi 文生圖的介面下,我們可以通過文字描述(提示詞-prompt)搭配不同採樣演算法,迭代步數,CFG值…等參數的設定,去控制圖像模型生成我們所想要的圖片內容。
整篇分5個區分段來介紹
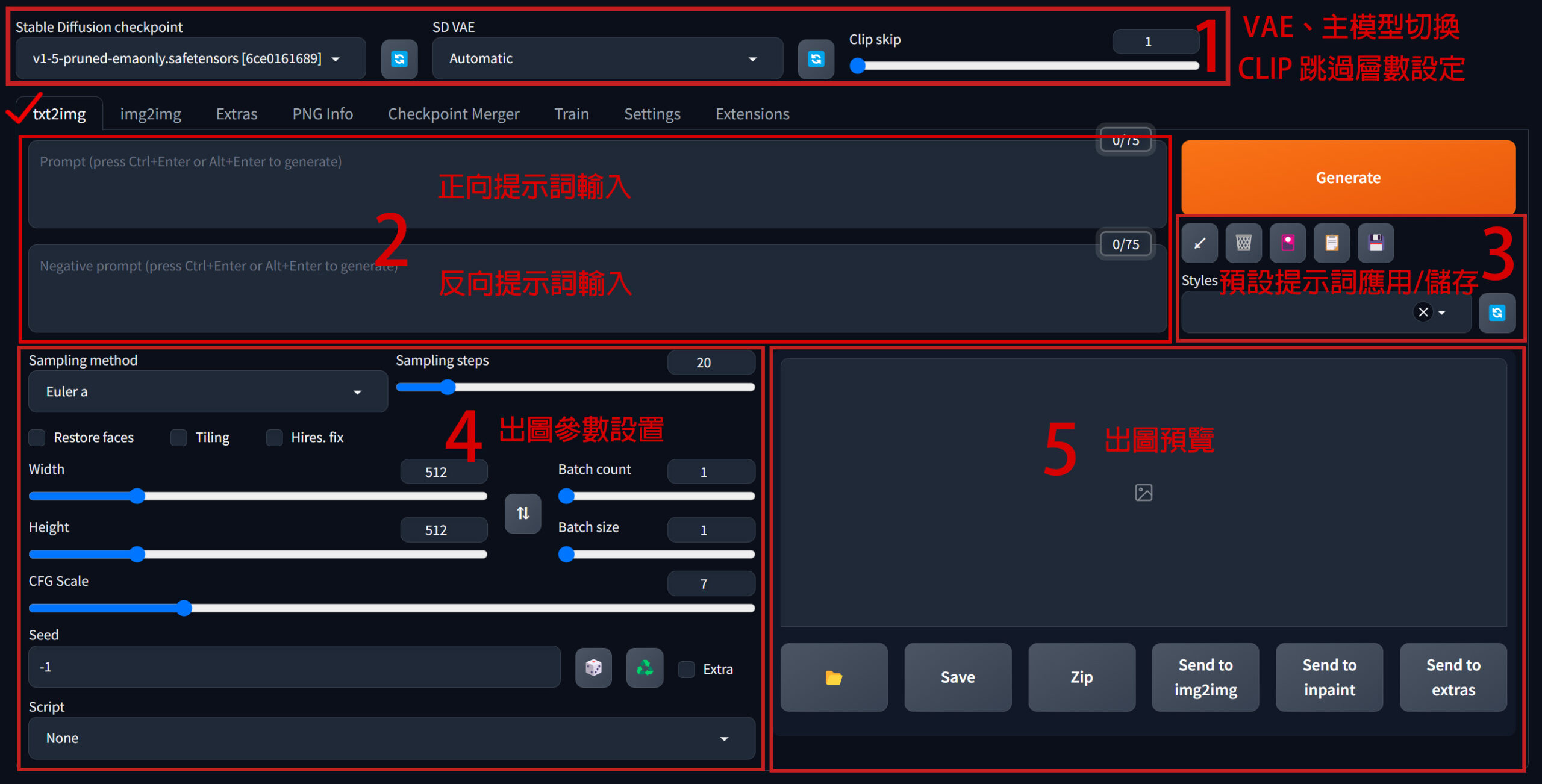
VAE、主模型切換 & CLIP skip
預設的WebUi並不會顯示出VAE模型切換(SD VAE)和CLIP跳過層設定(Clip skip)的操作選項,我們需要先到”Settings”標籤頁裡進行介面設定。

在”Settings/User interface”中找到Quicksetting list欄,在欄位中輸入關鍵字自動就會出現可用選單供選擇,把sd_vae和CLIP_stop_at_last_layers加進來。

每次修改完Settings裡的內容後,記得都要”Apply settings”後再”Relaod UI”,修改的內容才會顯示出來。

VAE、主模型切換
從網站上下載的Checkpoint和VAE模型,分別放進各自的資料夾後,就可以在下拉選單中找到並切換使用。如果是在WebUi介面正開啟使用狀態下另再加入的模型,要先點擊選單旁的刷新鈕,才會將剛放進的模型讀取進來。
Checkpoint放置位址 : WebUi程式資料夾\models\Stable-diffusion
VAE 放置位址 : WebUi程式資料夾\models\VAE
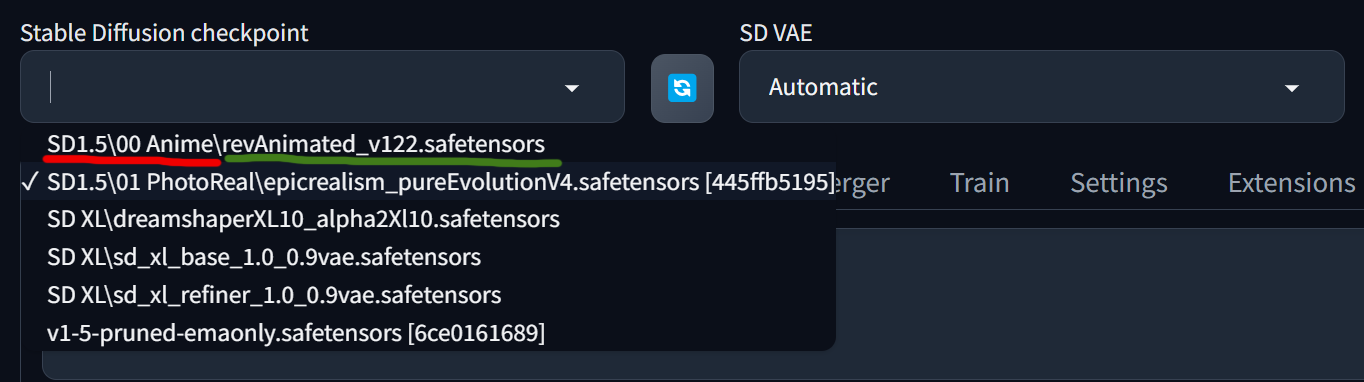
而在這些放置模型的資料夾底下,我們可以按自己使用習慣再新增建立不同的資料夾來將模型進行分類放置,以方便未來當下載的模型愈來愈多,選單落落長時,也能快速找到所需的模型。(ex. ….\SD1.5\00 Anime)
CLIP skip
先看名稱有CLIP(Contrastive Language-Image Pre-Training),我們就可以知道,這裡在圖片生成過程中主要是介入到 “Prompt轉換給Stable Diffusion理解/參照”這段。一般使用時,都是默認的預設數值就好,如遇到模型在使用說明中有特別提到使用指定的clip skip數值會產出較理想結果時,再來使用即可。
從網上相關的原理說明來看(想深入了解原文解釋的可參考網址中Clip Skip這段說明→ 網址連結)。我的理解就是,文字資訊Prompt的內容是會被分層分類,一層層推進過濾,愈分愈細,最終Stable Diffusion就會以讀取到的分層分類後的資訊進行繪圖。(ex. 人類分成男性、女性→女性又再分成女孩、女人→女人又再細分下去,可能是依人種、髮色、穿著、動作…等不同特徵來分類。)
而Clip skip的數值範圍從1~12(層),如果我需要完整保留prompt所有細節描述精準的產出,那就不要跳過任何一層分類(這裡是數值1),如果我想讓Stable Diffusion在不同程度/內容細節上可以更自由發揮創意,那就把數值逐漸拉高(跳過更多分類層)測試看看。skip數值愈大,所生成的圖像也愈偏離提示詞內容,但同時Stable Diffusion也能較不受提示詞限制,在更廣的分類層下有更多的素材內容可以取用作圖。
下面測試了2個案例
案例一、提示詞是”a girl, black long hair, wearing sunglasses”。
Clip skip1~3之間,所有提示詞的內容都有呈現符合,一個女孩、黑色長髮,戴著太陽眼鏡。
Clip skip4~6之間,髮色開始跑掉不是指定的黑色。
Clip skip7之後太陽眼鏡都不見了,且有的髮色不是黑色,有的變成短髮。

案例二,提示詞只有”a cat”,當Clip skip的數值愈高,就開始愈來愈不像貓,神態長得開始往狗/或其它動物的方向去。

正、反向提示詞輸入
正向提示詞(Prompt)就是我們需要畫面中出現的內容,但有時生成的圖片雖然都符合了我們所描述的同時,畫面中也可能會多出一些其他我們不想要的內容,這時就需要利用反向提示詞(Negative Prompt)去告訴Stable Diffusion,我不要什麼。
下面是提示詞的一些基本格式寫法和原則。
- 提示詞可以是單字、單詞或是短句。
“1girl, beautiful, sitting, sofa”
“a beautiful girl, sitting on the sofa”
“a beautiful girl is sitting on the sofa” - 不同關鍵詞間以英文逗號分開,逗號前後有無空格不影響生成內容。
- 放在愈前面的提示詞,權重愈高。
- 增強/減弱提示詞權重的寫法 :
– (提示詞:權重數值), 權重數值一般默認為1,低於1減弱、大於1加權,0.1~2之間較不會讓畫面崩壞。 ex. (one girl:1.2),(red hair:0.8)
– (提示詞) = 增強1.1倍權重,((提示詞)) = 增強1.1*1.1倍權重。ex. (one girl) = (one girl:1.1)
– [提示詞] = 減弱1.1倍權重,[[提示詞]] = 減弱1.1*1.1倍權重。 - 混合 : 利用”AND“進行多種元素強制融合。 ex. 1cat AND 1dog = 產生出來的圖像會同時具備貓和狗的特徵。
變化方式可以利用” :數字”來加權重。ex. 1cat AND 1dog:1.6 = 產生出來的圖像會同時具備貓和狗的特徵,但會更偏向狗的特徵。 - 交替換算 : [提示詞1|提示詞2] = 提示詞1、2交替演算(一步畫提示詞1、一步畫提示詞2,反覆交替),成像會更偏向前面的提示詞,功能類似AND。ex. [1cat|1dog]
- 漸變 :
– [提示詞1:提示詞2:數字] = [from:to:when] : 數字大於1時,理解為第x步以前生成提示詞1,第x步開始生成提示詞2。ez. [1cat:1dog:20]=1~19步生成貓、20~生成狗。數字小於1時,理解為百分比%。
– [提示詞:數字] = [to:when] : [flower:20] = 從第20步開始生成花,[flower:0.5]=總步數的50%開始生成花。
– [提示詞::數字] = [from:when] = [flower::20] = 到第20步停止生成花,[flower:0.5]=到總步數的50%停止生成花。
來測試一個漸變的案例 :
提示詞是 : [1cat:1dog:20],總步數(Steps)為40。很明顯20以前都是在生成貓,20以後開始加入/生成狗的外貌特徵。

預設提示詞應用/儲存
對於一些每次生成圖像時都會用到的提示詞,像是”best quality, masterpiece….等提高畫質”的prompts,我們可以把它儲存起來,這樣下次使用時就不用再重新從頭輸入一遍。
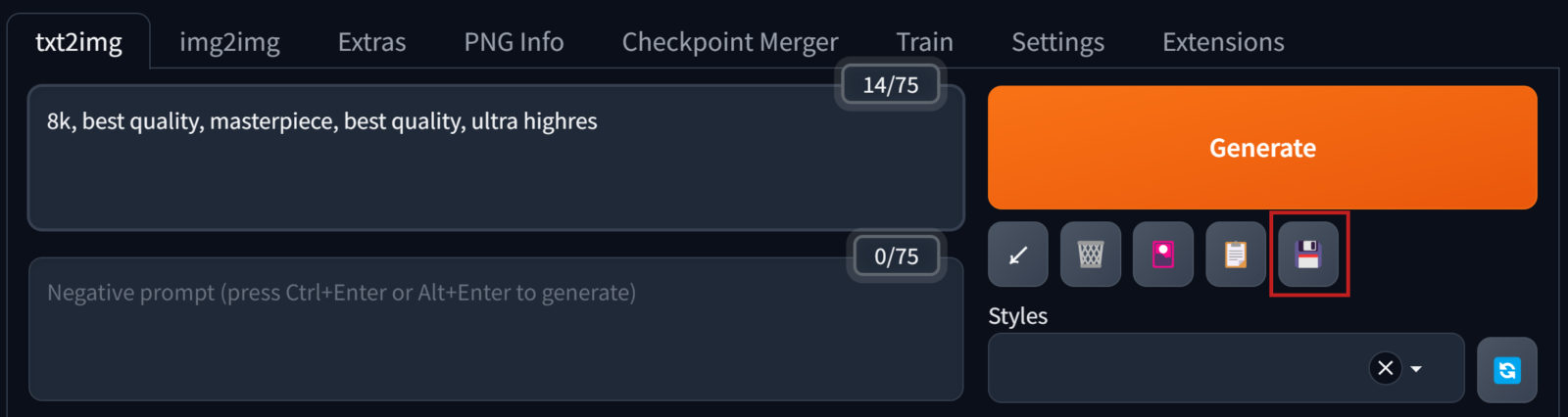
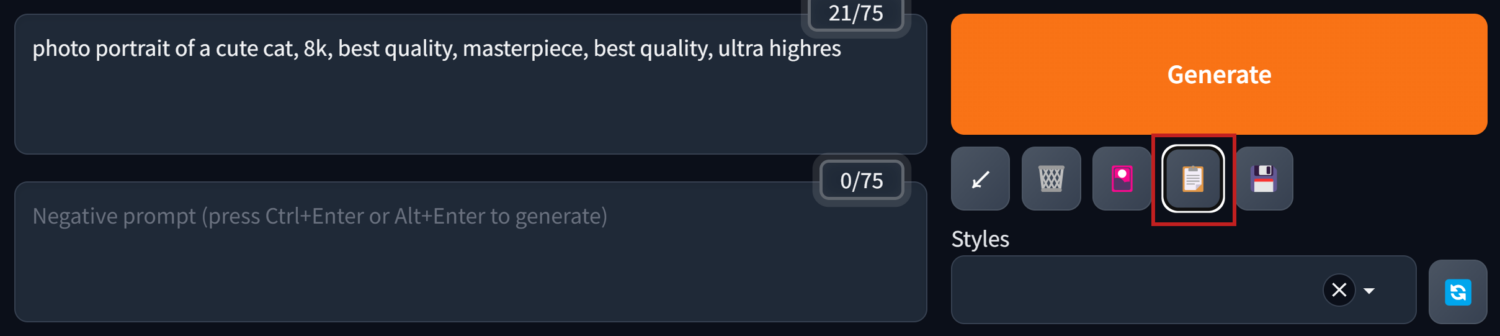
之後就可以在Styles的下拉選單中呼叫出來使用。生成圖像時,除了prompt框裡輸入的文字,Styles裡所選取的預設提示詞內容也會被讀取。
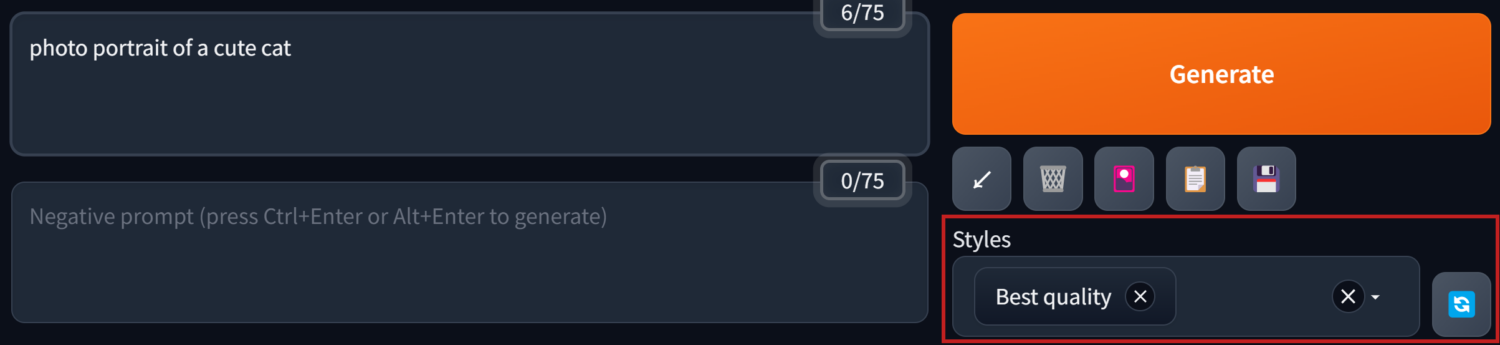
這個按鈕可以把選進Styles裡的提示詞全部還原展開放進Prompt輸入框裡。
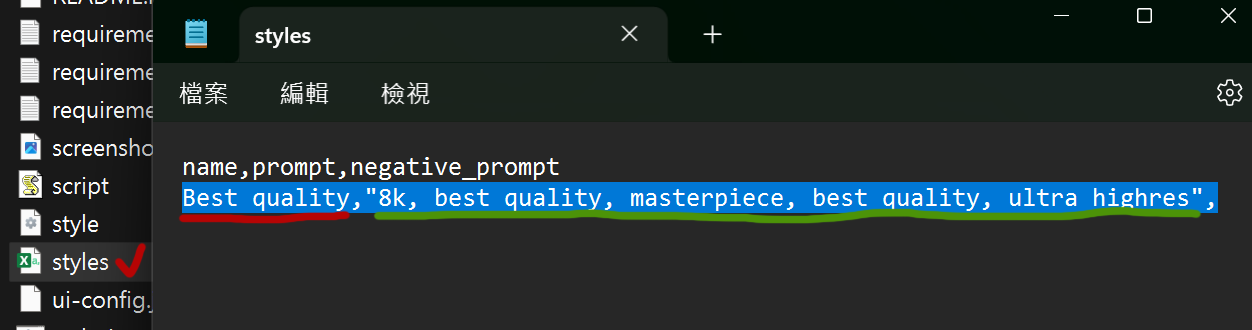
之後如果想要刪除修改Styles裡儲存的提示詞集時,可以到WebUi程式資料夾下找到styles文字檔。用記事本或excel打開後就可以開始進行修改。

垃圾桶按鈕是清空Prompt欄位裡的內容。
箭頭按鈕有兩個作用,當Prompt欄位是空白時,會還原恢復上一張圖的prompt、各項參數等設定資訊。或是我們在Civitai網站上看到喜歡的圖片,想了解所有參數是如何設定的,只要把這張圖的設定資訊Copy下來,全部貼到Prompt欄後,按下箭頭按鈕就會自動幫你把下方參數設定都套用好。
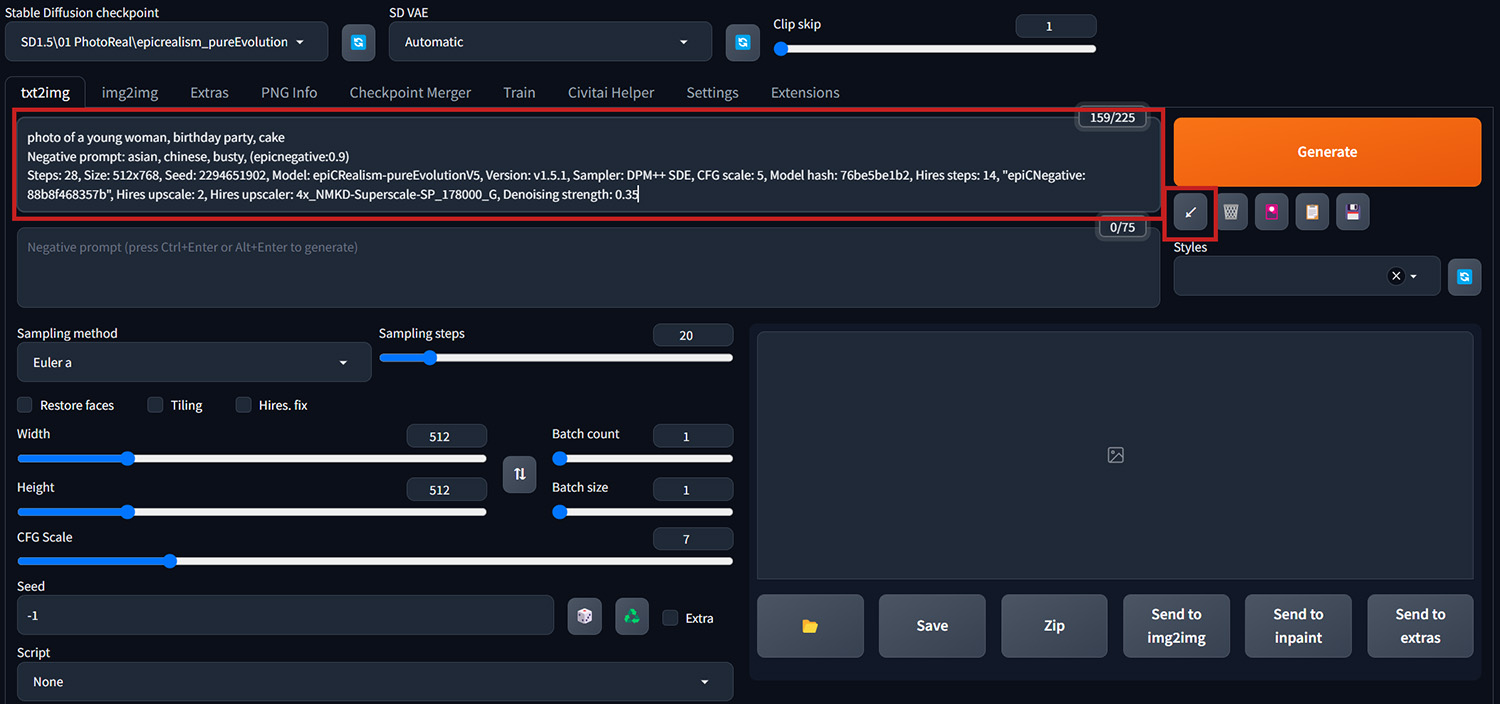

最後這個”小紅書”按鈕,可以叫出embedding(Textual Inversion)、Lora等輔助模型的選單。
模型檔案放置位址 :
Embedding : WebUi程式資料夾\embeddings
Lora以及LyCORI: WebUi程式資料夾\models\Lora
在這些放置模型的資料夾底下,我們一樣也可以另建立新的資料夾來對模型進行分類排序。
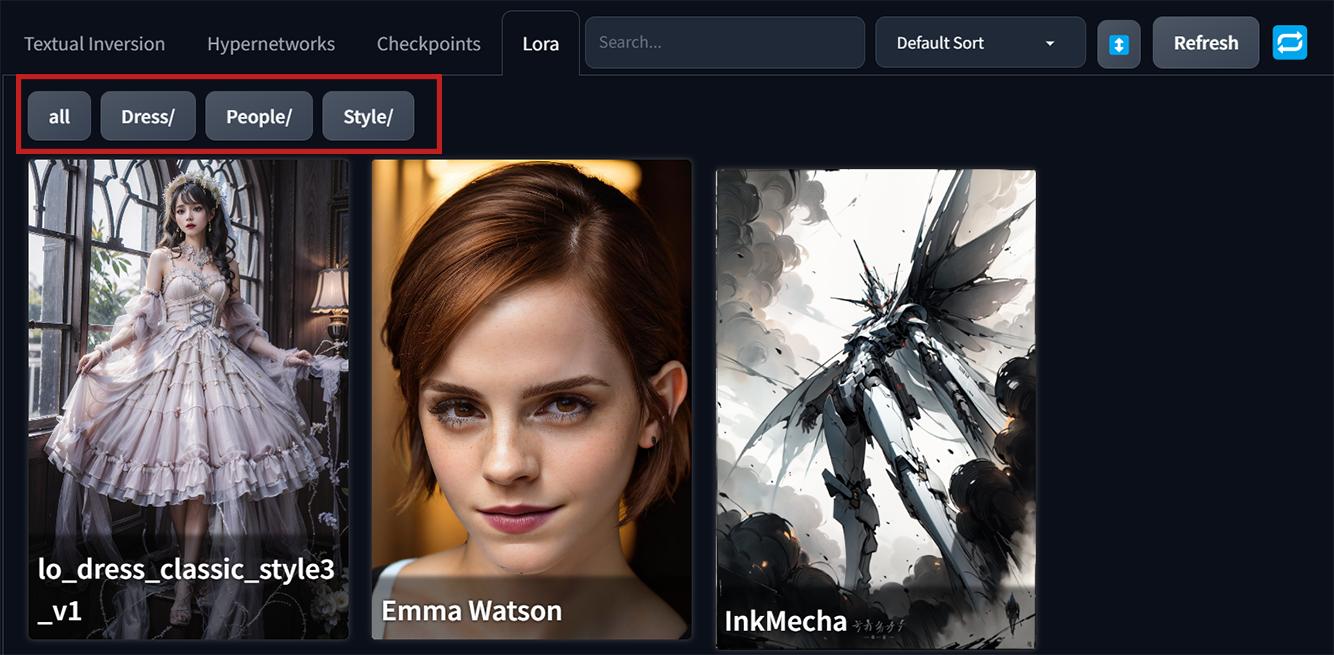
透過案例來比對一下套用embedding、Lora以及LyCORIS模型的出圖效果。
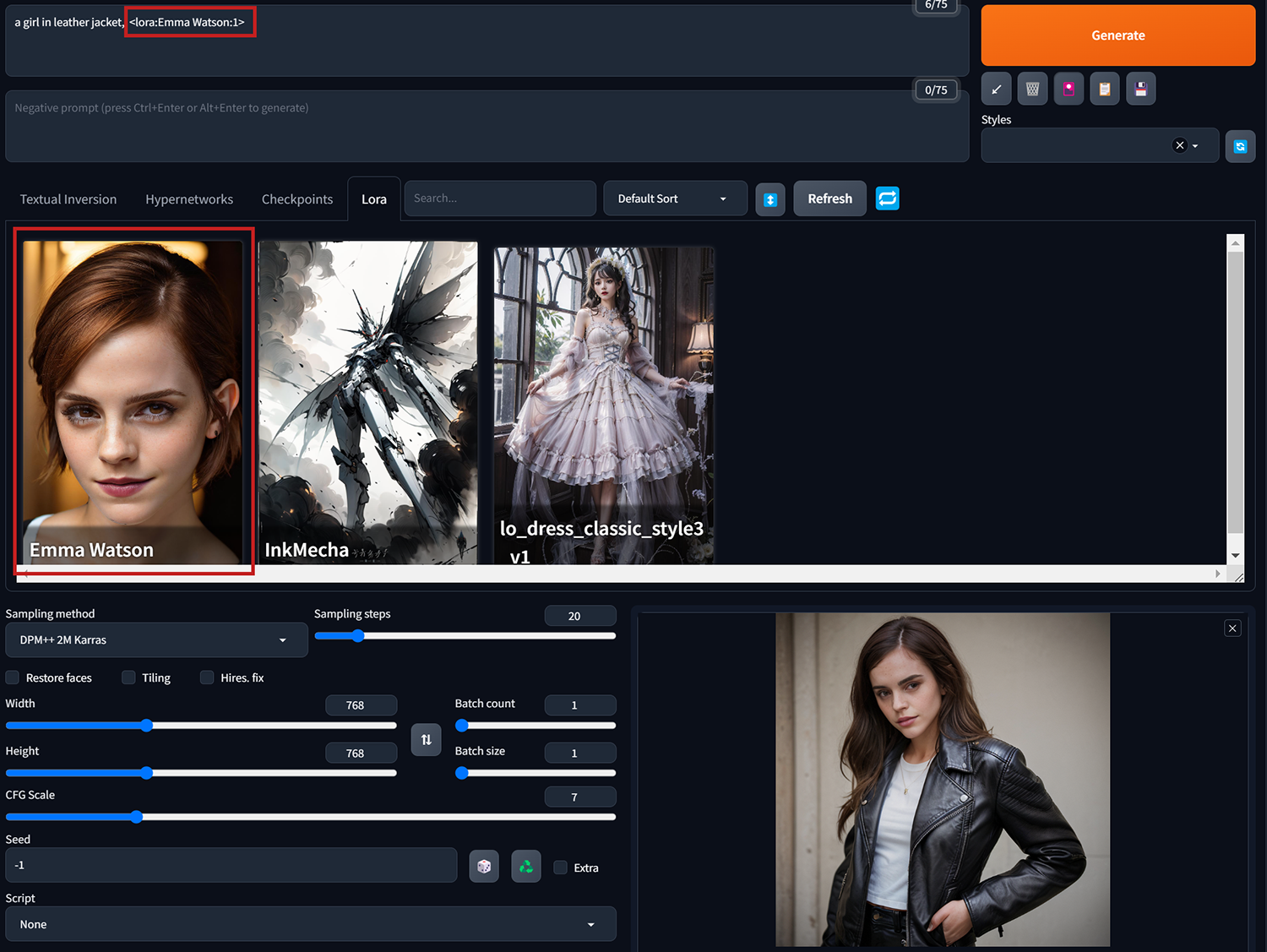
案例一、”a girl in leather jacket”
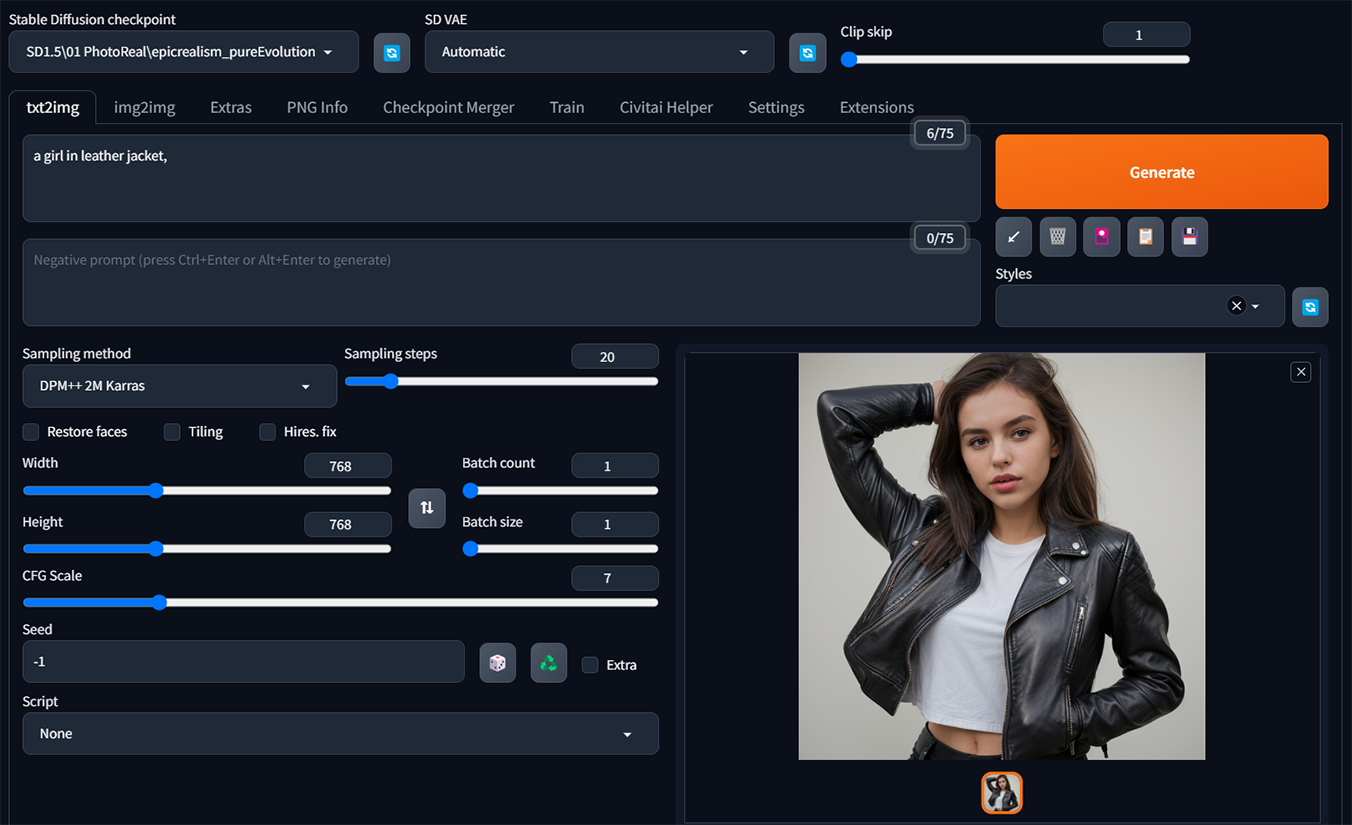
當其它所有參數設定都不變動,只套上Emma Watson的embedding(Textual Inversion)。按下小紅書叫出模型選單,點選要使用的Embedding, 讓這個embedding的”觸發詞(Trigger Words)”顯示在Prmopt欄裡。最後生成出來穿皮衣的Emma Watson。
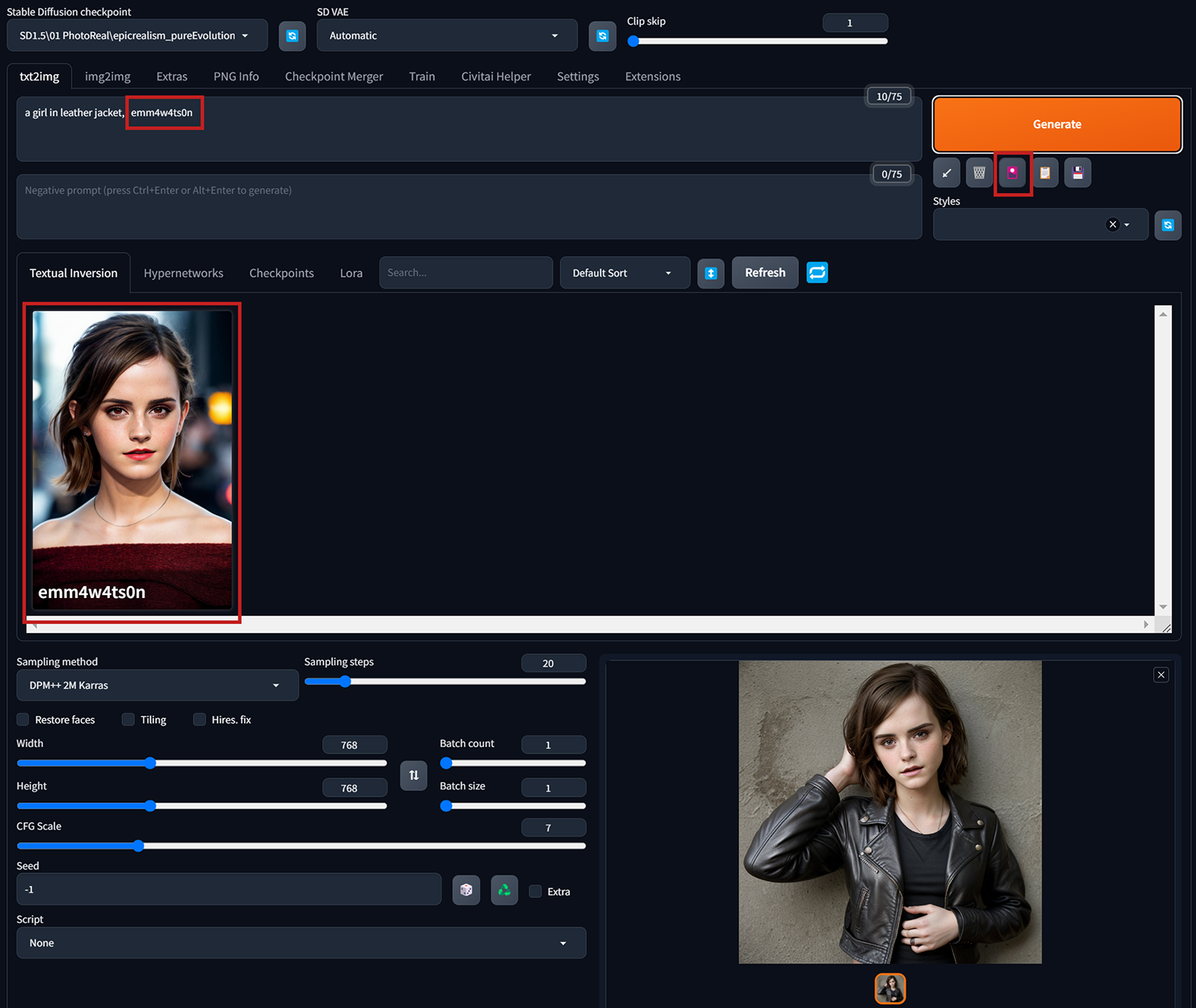
案例二、”a girl sitting on a chair”
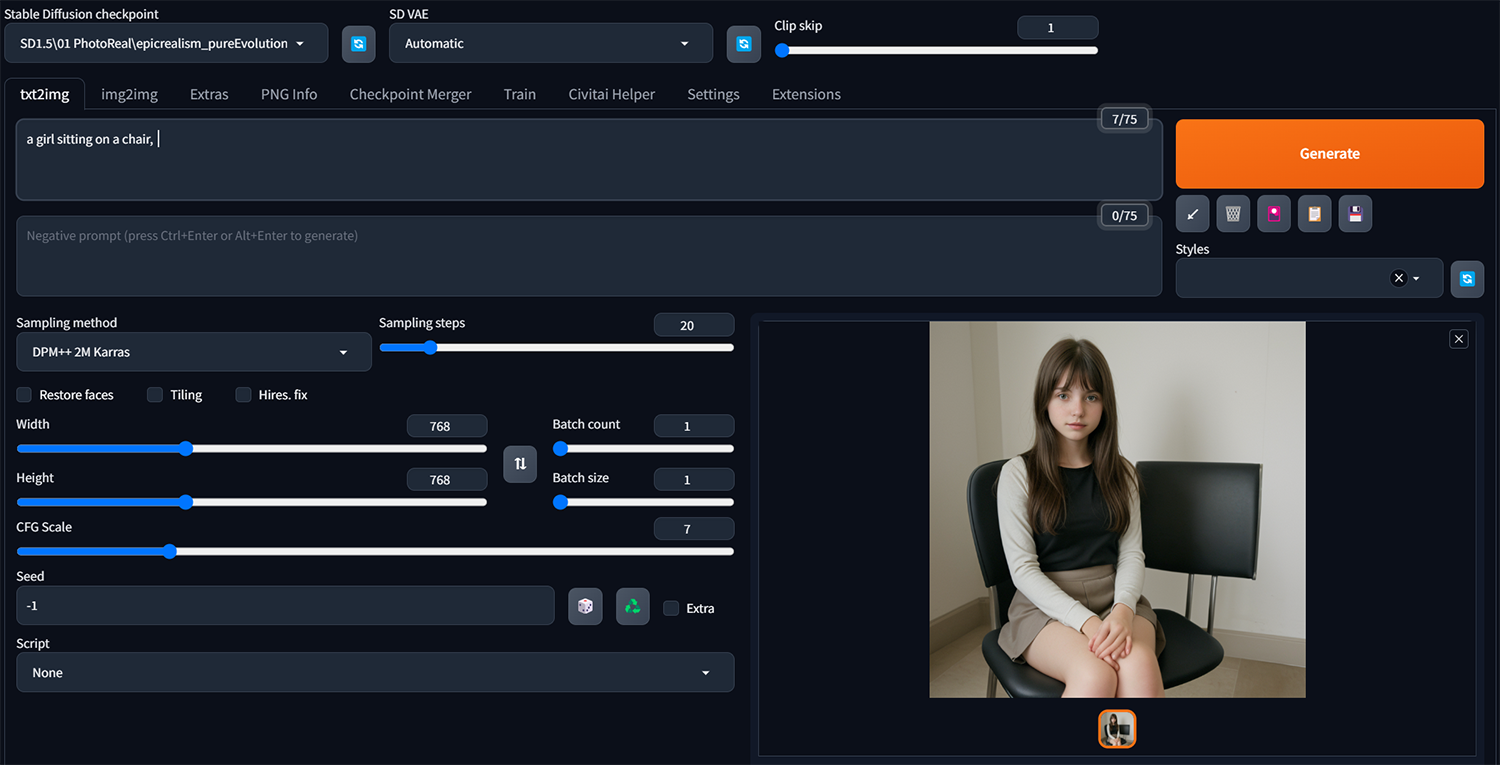
一樣所有參數設定都不變動,再添加讓人物穿上特定風格服飾的Lora。<lora:lo_dress_classic_style3_v1:1>,套用上的Lora,在冒號後面的數字代表權重,預設是1,可自行調整影響的權重。
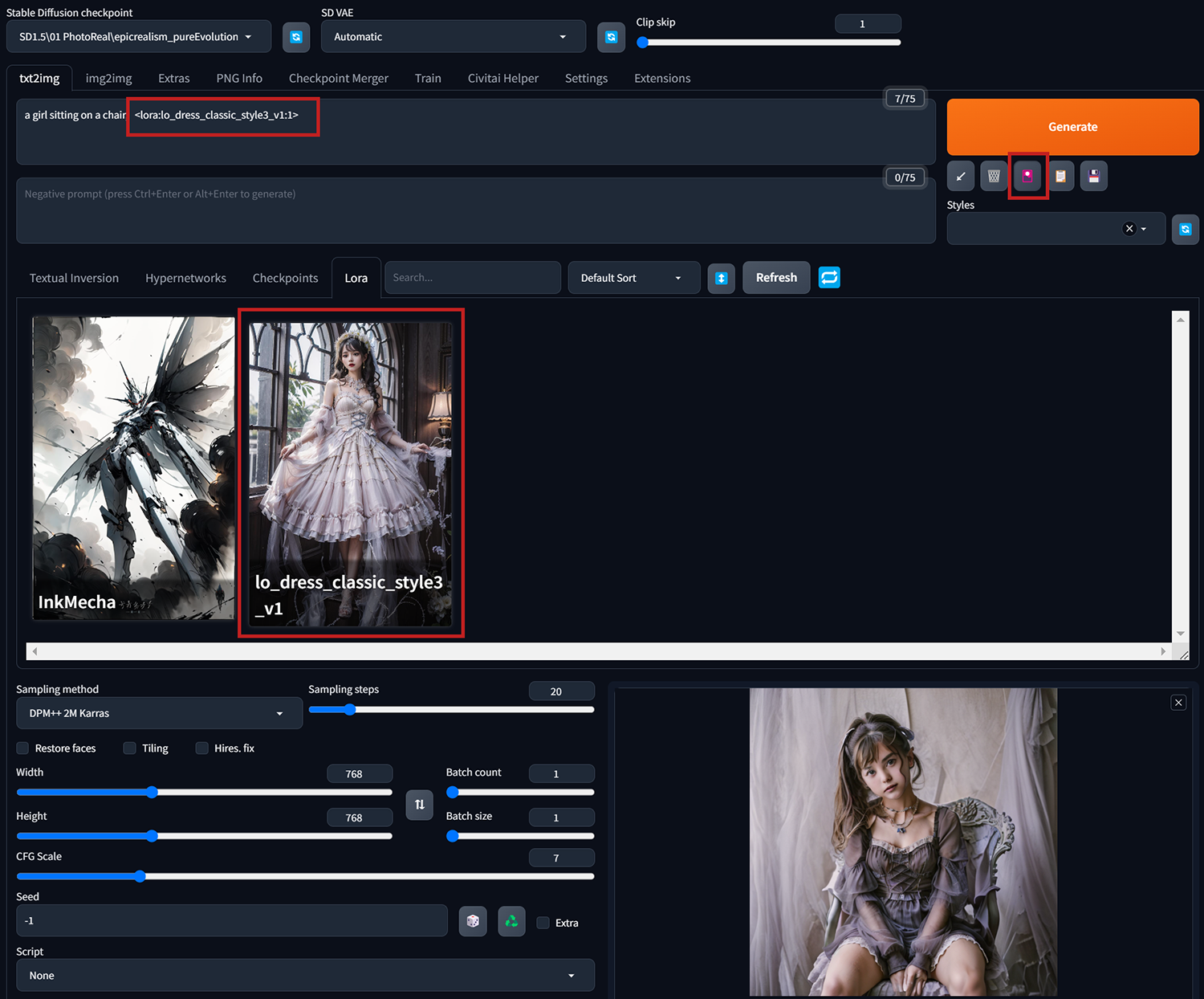
案例三、和案例一同樣”a girl in leather jacket”的設定,改套用Emma Watson的LyCORIS模型。
(PS. 自WebUi 1.5.0以後的版本,LyCORIS模型不需要再另外下載外掛就能直接使用,所有LyCORIS模型放置的位置和使用方法都和Lora一樣。)
出圖參數設置
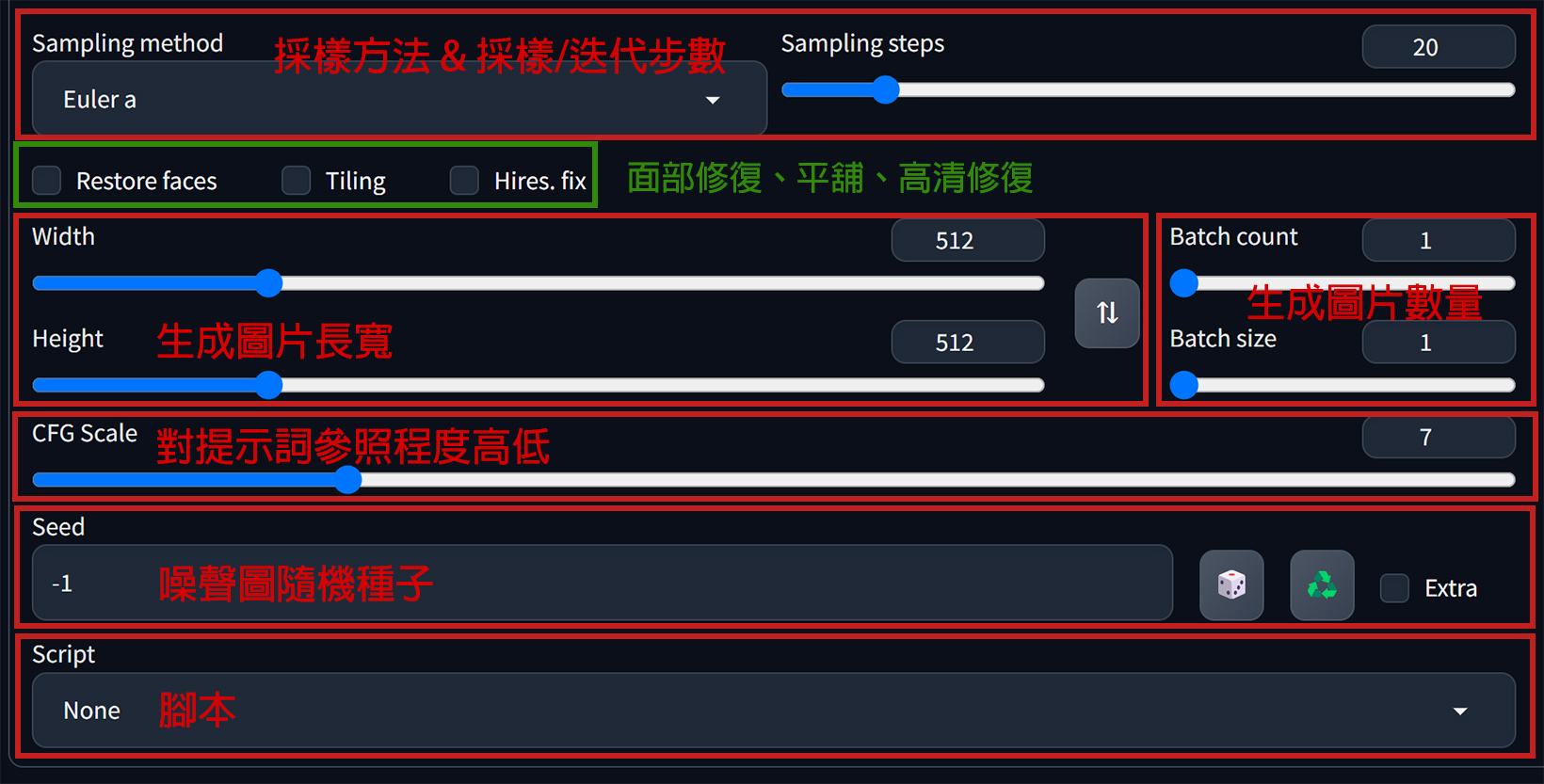
- Sampling method(採樣方法) : 根據不同的Checkpoint模型,都會有個別更適合使用的採樣方法。通常我都是直接設定使用Civitai模型資訊說明裡推薦的採樣方法。而每個採樣方法的出圖效率速度都不一樣,實際測試實驗對比可參考下列說明文章,有詳細說明。→ AI繪圖-實測:比較目前20種採樣方式的速度與圖片生成結果(stable diffusion webui)
- Sampling Steps(採樣/迭代步數) : 這裡是控制圖片去噪的步數,一般來說,步數愈高畫得愈細緻,但同時也更費時。根據使用的採樣方法不同,也都會有個別適合的步數範圍。一般我都是設在20~40之間。如果是動物有毛皮紋理特別需要細節呈現的圖像,就盡量拉高一些試看看(40左右)。
- Restore faces (面部修復) : 生成人像圖如果出現”臉崩/面部畸形”的情況時可開啟使用。但這比較適合在畫三次元真人人像時使用,二次元的圖不適合(反而成像效果更差)。
- Tiling (平舖) : 生成可平舖的圖(Seamless Pattern)
- Hires. fix (高清修復) : 假設畫一張512*512全身人像時,由於臉部在畫面中所佔的比例很小,所被分配到的像素/噪點不夠多,生成的人臉就很容易崩壞。如果此時開啟高清修複功能(假設放大2倍),原本512*512的圖變成1024*1024,臉部也因此按比例多增加更多的像素/噪點可用(SD有更大的空間去針對臉部作畫/畫更細緻),就可修復原本崩壞的人臉。
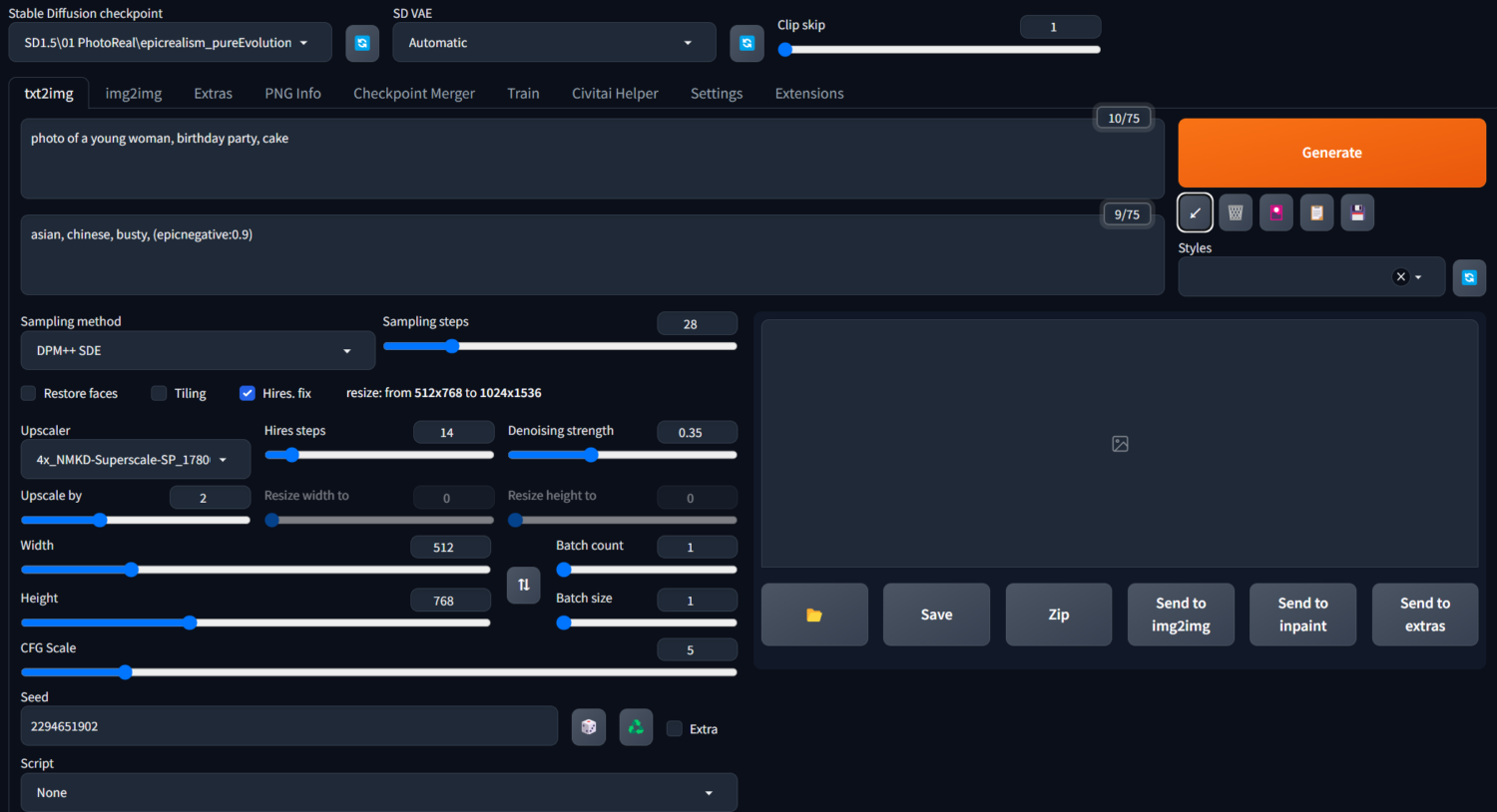
勾選Hires. fix後另展開的設定選項如下圖 :
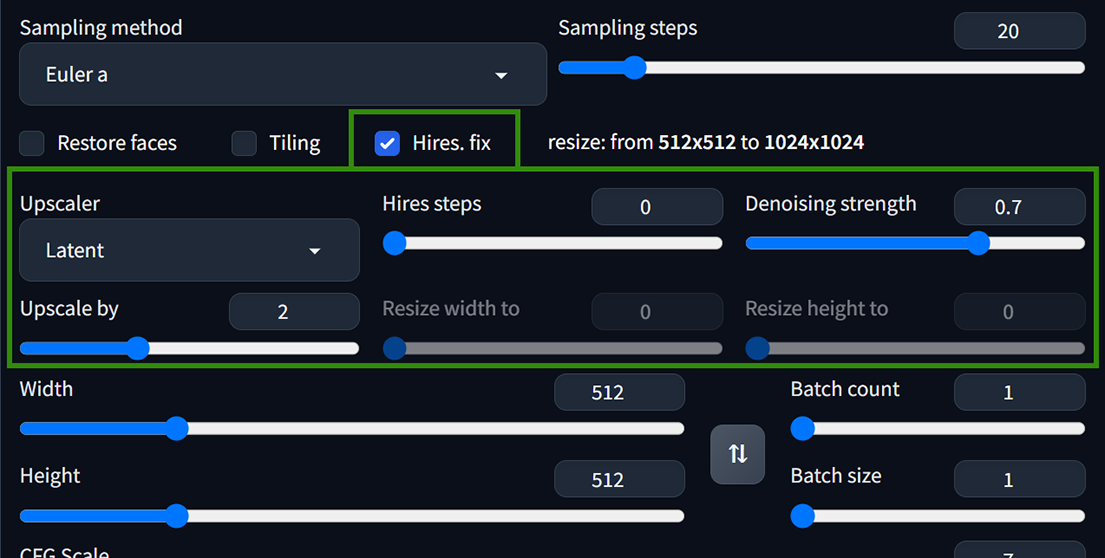
– Upscaler (放大演算法) : 在預設的放大演算法清單中,建議使用R-ESRGAN4x+(畫真人/三次元)、R-ESRGAN4x+Anime6B(畫動漫二次元)。
– Hires steps (高清修復採樣步數) : 設置為0時代表與原始圖像生成的採樣步數一樣。
– Denoising strength (重繪幅度) : 數字越低,對原圖產生的變化越少,但同時對臉部的修復效果也較不明顯。一般通常設置在0.4~0.7間平衡修復和維持原圖關係的效果較剛好。 - 高清修復和面部修復最好不要同時開啟使用。
- 圖片寬高設定 :
– Stable Diffusion1.5版本是用512*512的圖去訓練出來的模型。如果寬高設定超過這範圍,整個畫面的構圖容易會出現奇怪的重複(ex. 人物有2顆頭、連體嬰….),因此寬高設定盡量至少其中有一邊設在512-768之間。
– 想要生成大圖時,可先生成512或768的小圖,再勾選啟用高清修復重繪放大。這樣構圖內容就不會出問題的同時也能生成高清的大圖。又或者在文生圖裡先生成小圖,之後再把小圖丟到圖生圖(img2img)裡重繪放大。在這裡大家應該了解到,其實在文生圖裡的高清修復(Hires. fix),就等於是先把圖生圖裡重繪放大的功能提取出來併到文生圖的介面裡同時一次出圖使用。 - 生成圖片數量 : Batch size拉高容易爆顯存,如果想一鍵同時生成多張圖又不想爆顯存的話,調高Batch count數量較適合。
- CFG Scale – Classifier Free Guidance Scale (提示詞相關性) : 官方定義是指用來調節提示詞對擴散過程的引導程度。數值越高越偏向提示詞內容生成,數字越低,Stable Diffusion就越自由發揮,忽略提示詞內容。
數值設定建議 :
0-1時 : 圖像崩壞
2-6時 : 生成圖像比較有想像力(漸偏離文本內容)
7-12時 : 普遍效果較好,既有創意也能遵循文字的提示詞
10-15時 : 提示詞影響生成圖像更多,另畫面的對比飽和度也會上升
18-30時 : 畫面逐漸崩壞,但另再拉高採樣步數可以降低崩壞程度
- Seed (隨機種子) :
– 數值為 -1 時,每次隨機產生不同的噪聲圖。如果是指定的種子數值就會產生同樣的噪聲圖。
– 在種子數值和其它所有參數設定都一模一樣的條件下所生成的圖會近99%相似,但仍不會100%一樣(神經網絡工作的原理不會產生100%一模一樣的圖)。
勾選Extra,會展開另一個隨機種子選項。(這個Extra的Seed平時不太會用到)
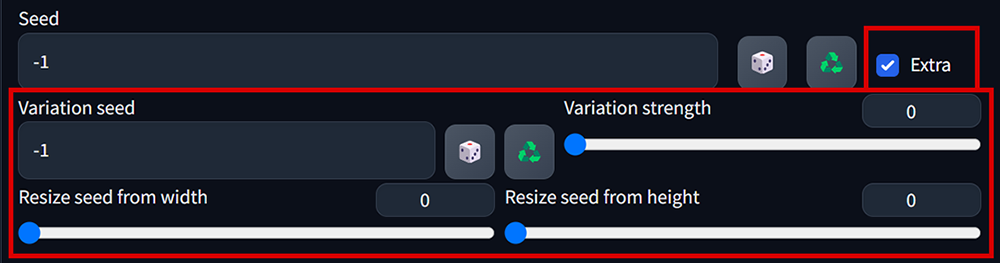
- Variation seed (差異隨機種子) : 生成圖像時,同時產生另一張噪聲圖,調整差異強度去控制生成的圖像。
– 強度設定0時,用Seed的噪聲圖去生成的圖像
– 強度設定1時,用Variation seed的噪聲圖去生成的圖像
– 強度設定0.5時,用2張種子的噪聲圖按比率去生成的圖像
Script(腳本)
- X/Y/Z plot : 方便用來一次生成多張圖對照、測試各參數、模型對出圖成像的影響。
如下圖所示,我想知道Euler a 和 DPM++ 2M Karras兩種採樣器,在不同採樣步數時的成像效果。可以這樣設定 :
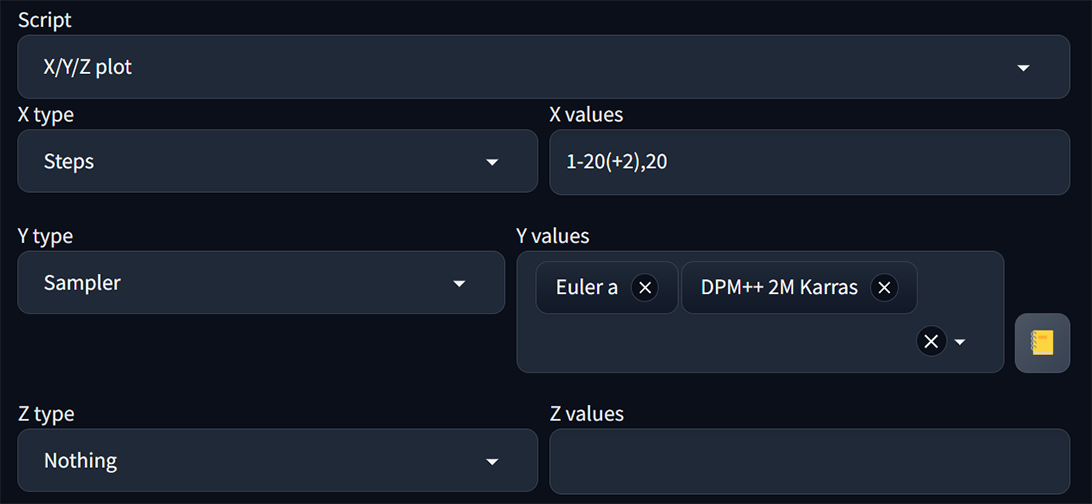

在此Steps 採樣步數的寫法可以是 :
(1) 步數每次加1 : 1-5 = 1,2,3,4,5
(2) 不同步長 : 1-20(+2) = 1,3,5,7,9,11,13,15,17,19
(3) 規定範圍內出多少個圖 : 1-10[5] = 1,3,5,7,10
- Prompt Matrix (提示詞矩陣)
腳本選擇提示詞矩陣後,在Pompt欄裡輸入 :
正常提示詞 | 測試改變提示詞1 | 測試改變提示詞2 | 測試改變提示詞3…..
ex. a girl|hat|sunglasses|mask

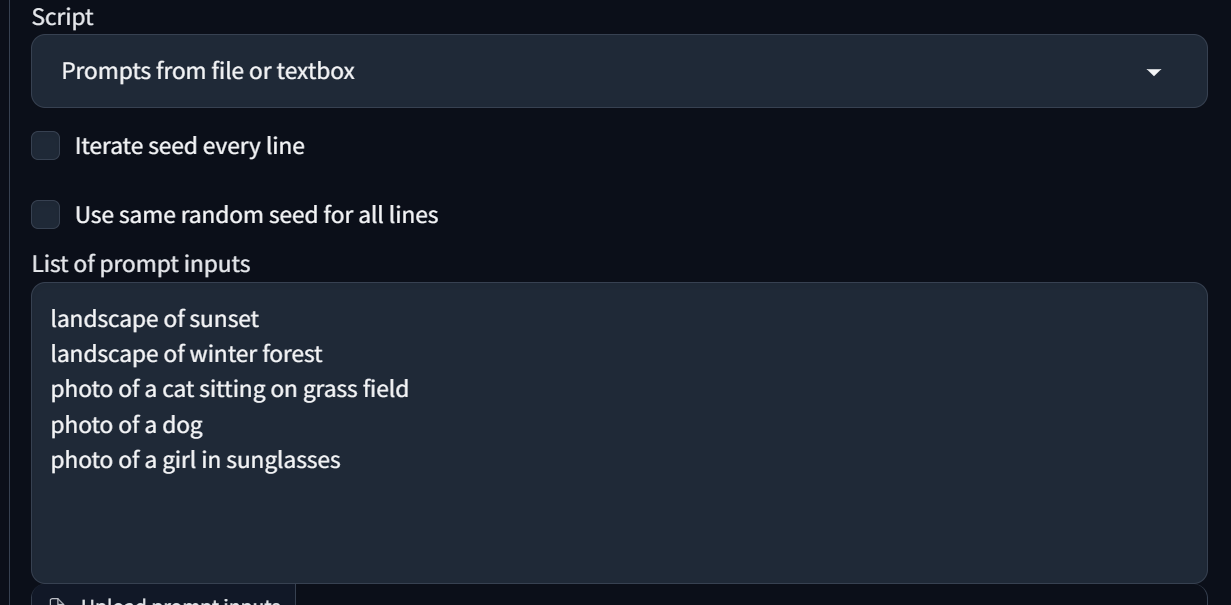
- Prompts from line or textbox , 批量生成不同提示詞的圖像
每張要生成圖像的提示詞換行分開,之後就會一次生成5張不同提示詞內容的圖片。
出圖預覽區
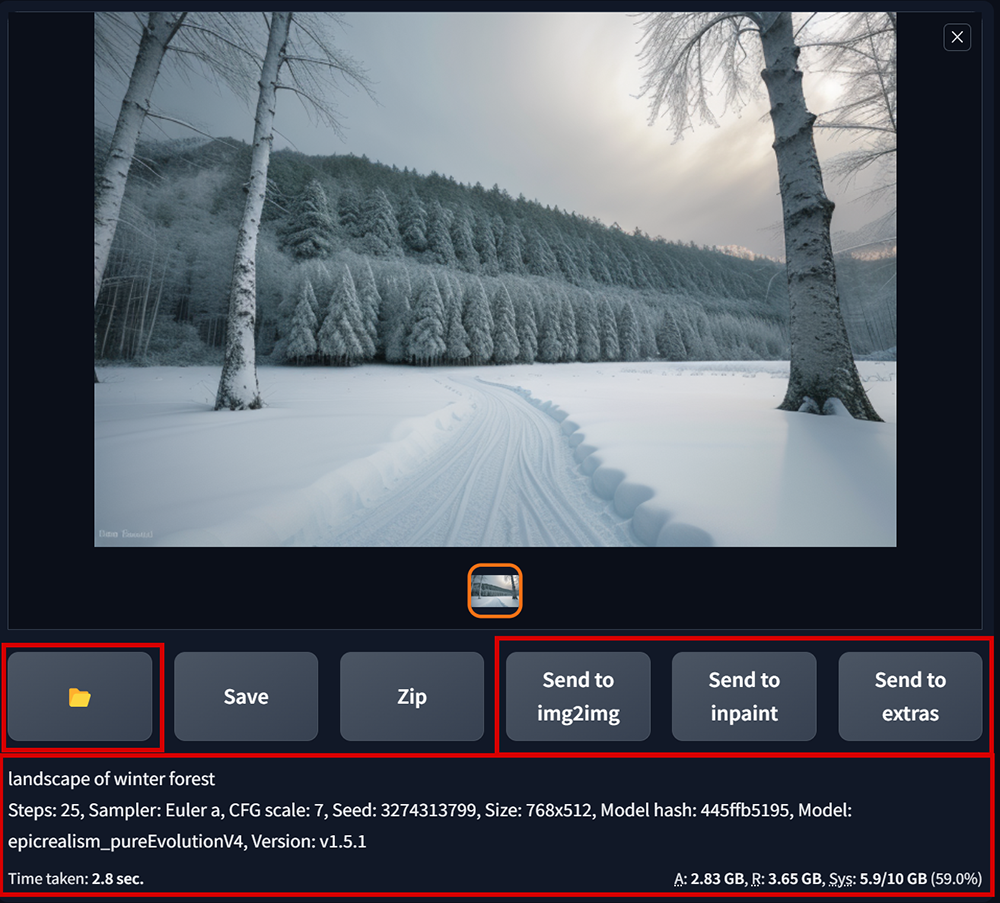
- 資料夾為開啟圖檔所在位置。所有Stable Diffusion產出的圖都會放在 : WebUi程式資料夾\outputs
- 可在此將預覽的圖送到img2img、inpaint、extra功能頁下去進行重繪、局部重繪、放大的作業。
- 圖順利算完時,這裡會出現該圖的所有提示詞、參數設定的訊息。如果算圖失敗(爆顯存或是其它錯誤情況發生時,這裡就會顯示錯誤相關訊息的提示)
~下方拍手按個讚(每人最多可按5次讚),鼓勵一下吧,您的鼓勵就是店小二持續發文的動力~ 感謝 : ) ~
感謝店小二無私地分享,為我開啟ai大門~
期待之後還有其他的實驗分享,如圖生圖……..感謝